
09/11/2021
Back in the first decade of the 21st century, when genome scans cost huge amounts of money, the hot approach in genetics was called Candidate Gene. You look for a few gene variants of large effect because that was what it was possible to find, kind of like if you are looking for your car in a very poorly lit airport long-term parking lot at night and you don’t have a flashlight, so first you look under the handful of lamps because if it’s there you’ll find it. A few were discovered, but mostly this perspective didn’t pan out. Veteran behavioral geneticist Robert Plomin was in despair by the end of the decade.
But the second generation genome scanning technology that was introduced late in the 2000s was incredibly less expensive, so it became practical to do big data Genome-Wide Association Studies. These found lots of alleles of very small effect, setting off a race to assemble vast sample sizes in order to come up with Polygenic Scores that could be used to make predictions.
A big study led by James J. Lee in 2018 broke the million sample size barrier by stitching together dozens of databases from various studies that include DNA data with whatever demographic data was collected from each volunteer.
Say you are signing up for a study of kidney health that includes getting your DNA scanned. They aren’t very likely to give you an IQ test as part of this kidney study (why would they?), but they might very well include a question asking you to self-report your highest level of educational attainment. So, educational attainment has been the focus of big GWAS studies.
At this month’s International Society for Intelligence Research get-together, Lee presented highlights from his upcoming updated educational attainment study. By making a deal with 23andMe, they’ve boosted the sample size to three million, with moderate boosts in correlation score.
Russell Warne of Utah Valley U., author of In the Know, reported on ISIR talks:
Lee: Last GWAS’s sample size was 1.1 million. New sample size is 3,037,499. The entire contribution from @23andMeResearch. #ISIR2021
— Russell T. Warne 🇺🇸🇨🇱🇮🇱 (@Russwarne) September 3, 2021
Warne writes:
Lee: This brings the total of identified SNPs for educational attainment to nearly 4,000. Those SNPs explain 7% of educational attainment variation. Using all SNPs explains 12-16% of educational attainment. #ISIR2021

The top decile for polygenic score for educational attainment is about nine times more likely to graduate from college than the bottom decile. Back in 2018, with the million-plus sample, the top 20% was five times more likely to graduate from college than the bottom 20%.
Of course, few graduate from college solely owing to their own personal genes. College is often expensive in direct costs and always expensive in opportunity costs (wages forgone). Your parents having enough money for you to go to college can of course make a big difference. And your parents might have enough money for you in part because of their genes, so educational attainment is more complex than, say, IQ.
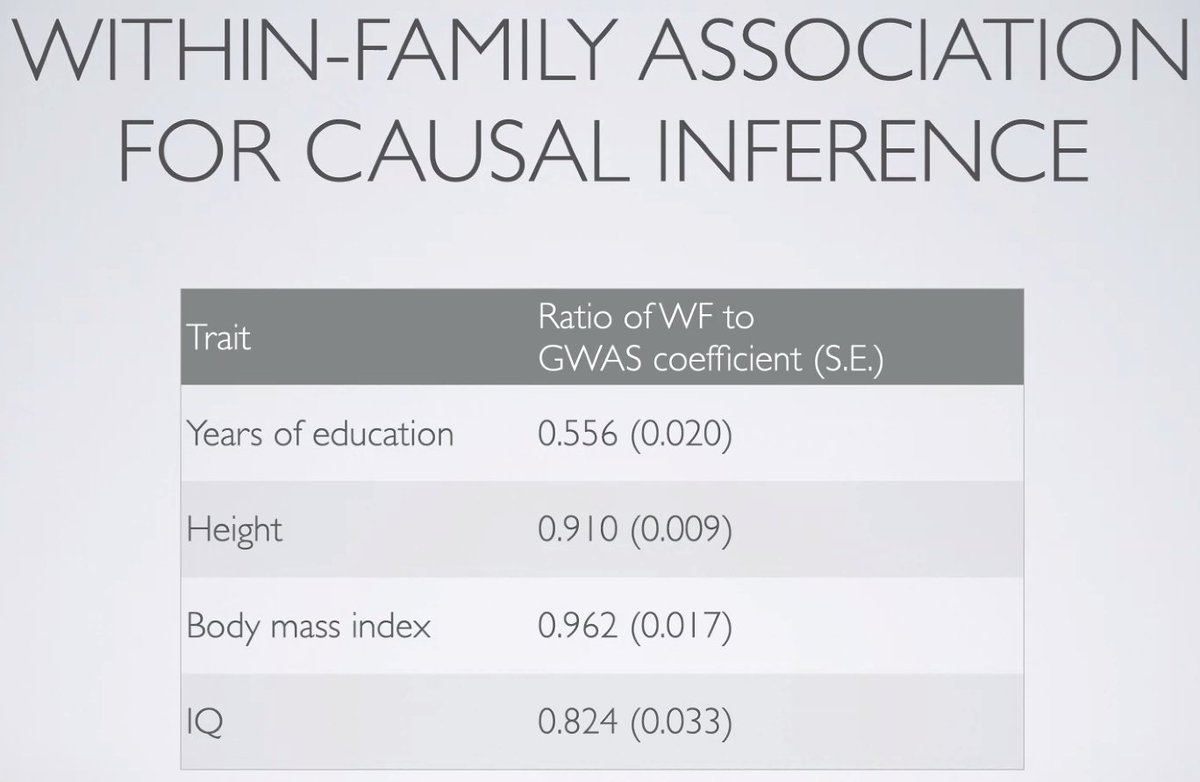
Lee: This can be corrected by examining SNPs to see which are predictive of educational attainment within families. Doing this attenuates the explained variance by about 55%. #ISIR2021
— Russell T. Warne 🇺🇸🇨🇱🇮🇱 (@Russwarne) September 3, 2021
Lee: Attenuation is not as strong for height, BMI, or IQ. Much more of the GWAS signal we find in IQ is causal. #ISIR2021
The following sounds interesting from a dating-and-mating perspective, but hard to wrap one’s head around:
Lee: This indicates that years of education is a proxy for something that people look for in a spouse, but it’s not necessarily IQ. We don’t really know what it is. 🤷♂️#ISIR2021
— Russell T. Warne 🇺🇸🇨🇱🇮🇱 (@Russwarne) September 3, 2021
Lee: Polygenic scores for educational attainment can be used to predict disease, and predictive power increases when combining that with a polygenic score for the disease. But that improved prediction is due often to the environmental confounding. #ISIR2021
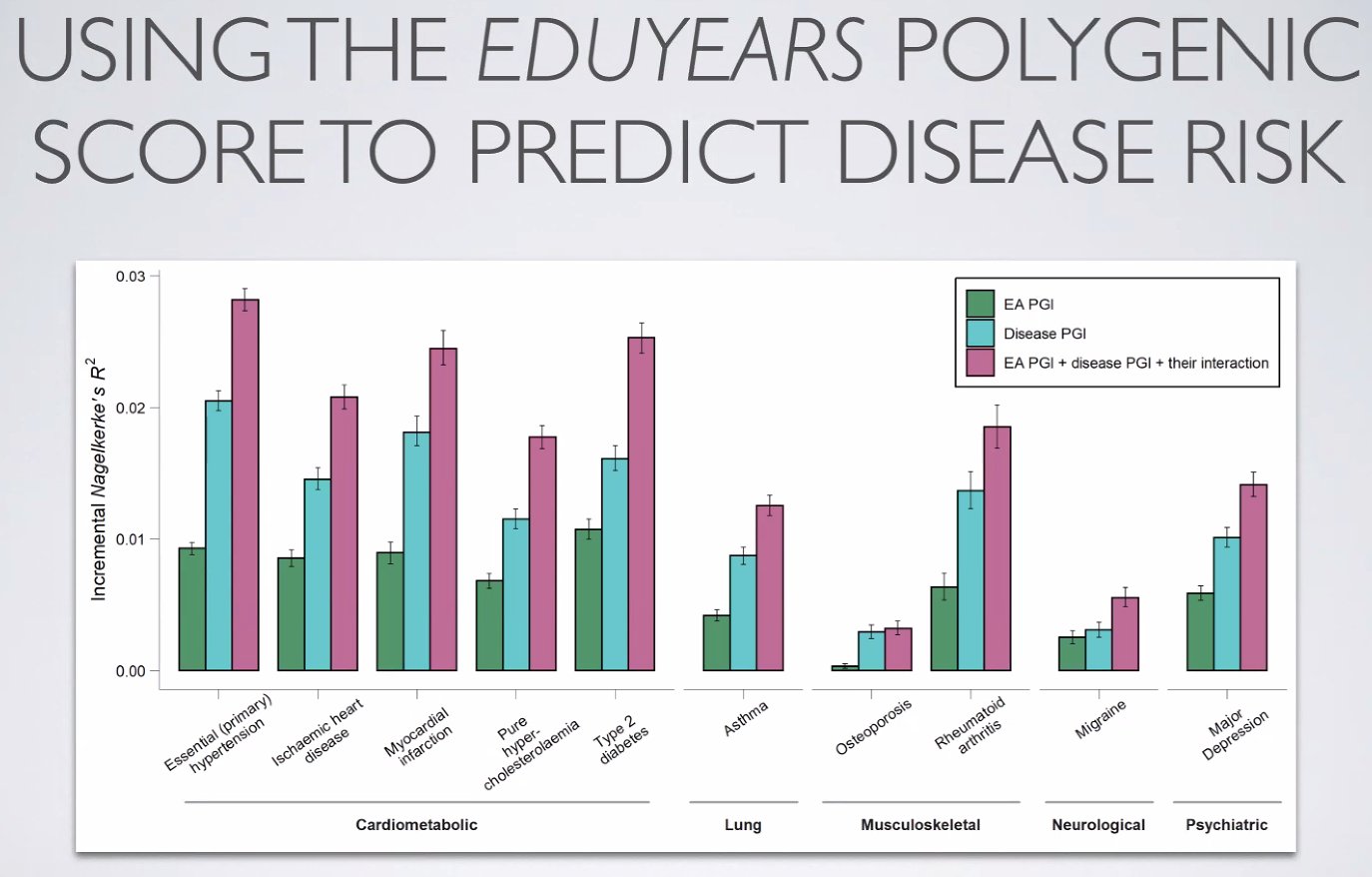
The polygenic scores for educational attainment complement the polygenic scores for predicting the disease for a number of diseases. The biggest boost from adding educational attainment PGS to the prediction model is from Type 2 diabetes, which, indeed, fits stereotypes about the type of person likely to suffer from diabetes.
But, keep in mind, these predictive models for disease are, at least so far, not terribly predictive.
This is a content archive of VDARE.com, which Letitia James forced off of the Internet using lawfare.